Posted on 03.01.2026
Goal: build a tiny convolutional neural network that learns to classify handwritten digits from small images.
Methodology: implement convolution efficiently (im2col + matmul), stack classic convnet layers, train with backprop + light data augmentation.
The mammal brain has a fascinating property of pattern recognition. The visual cortex can decode incoming optic nerve inputs, recognise previously seen patterns, and activate the corresponding neurons to that pattern. These neurons tell us what we are seeing.
In a classic machine learning problem we are trying to teach a model to recognise number digits from an input image. One way would be of course to feed the full raw image data to the model in a fully connected neural net and hope it learns to recognise the digits. But there is a better way, a way we can mimic what the visual cortex is doing in the human brain. We can take a smaller block of the input image and feed that to a small neural net. Then move this 'filter' across our image to purvey the full image. With this we are looking at the full image while saving massively in the amount of neural connections - aka weights we need. This technique is convolution.
We setup a CONV model that applies a MxM frame over the entire 2d input space, sliding by stride S. We end up with total L locations. We can have multiple filters W that will learn to recognise different patterns in the images.
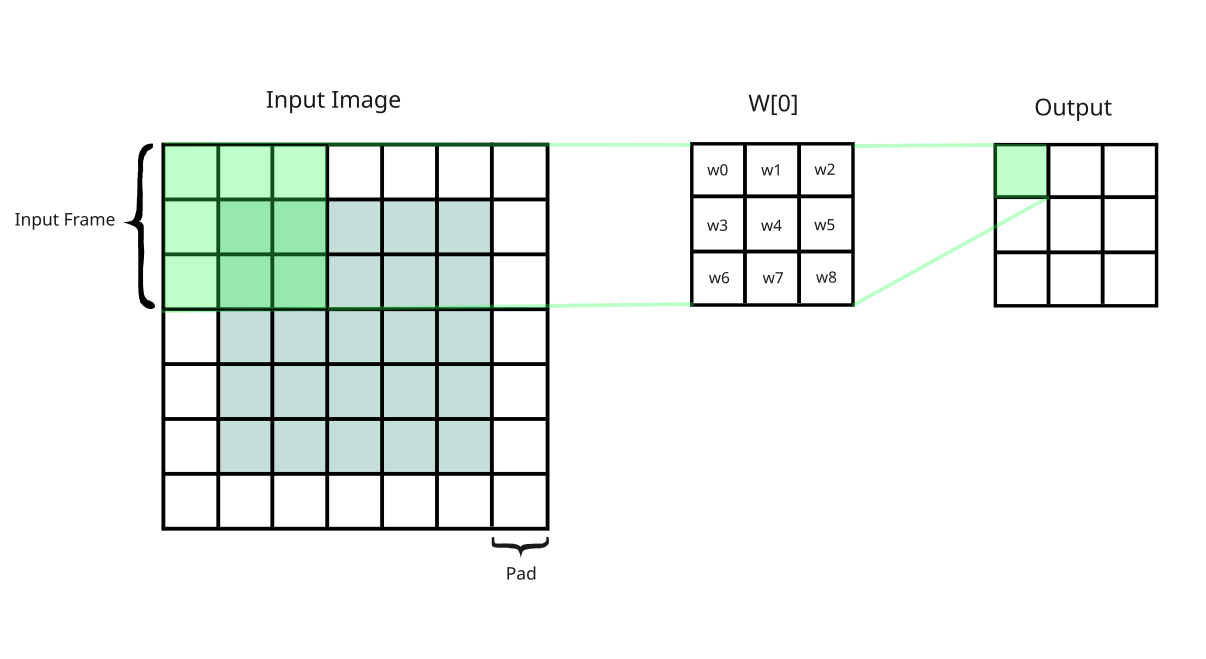
I can convert this frame operation into one matmul to have a whole lot easier time calling it on a GPU. Basically what i need to is place all of the pixels in an input frame to a column. So i end up with a X matrix of height MxM and width L. Then as the counter to that I place all of the weights in my filters to a matrix W_m. Where the width is MxM and height W. Now each matrix-multiplication operation multiplies the block with each filter weight and sums the result. Output is a matrix of size WxL.
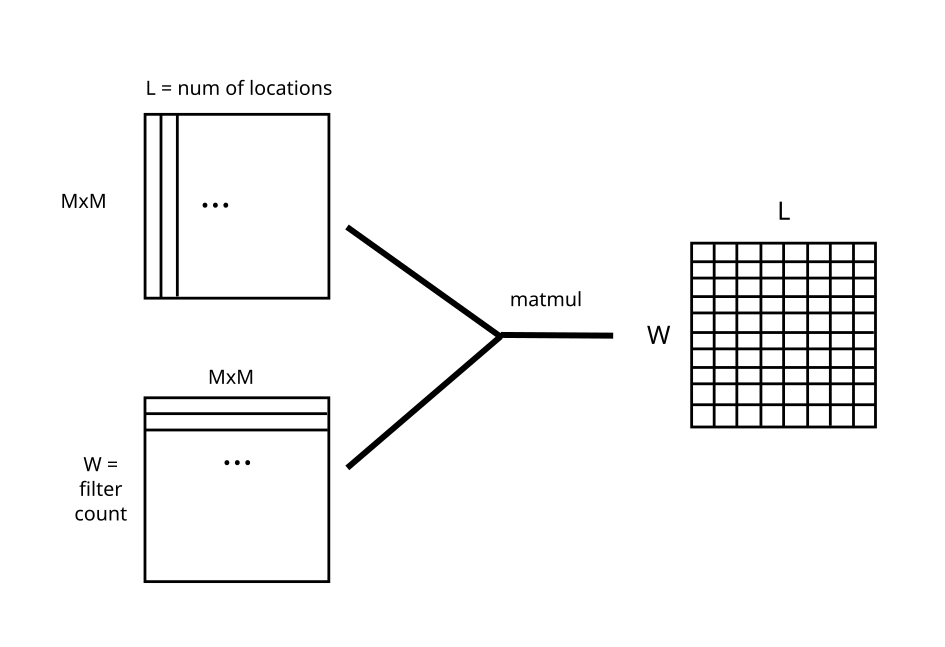
Then I can reshape the L dimension and map it to a X/Y to get a 3d output matrix XxYxW => input into next conv layer.
The convolution operation mentioned above is one layer type used in a convnet. Layer types:
I implemented a main layering function where i can modularly combine these layers in the convnet. My layer structure is as follows:
Final output is 10 values representing confidence that the input image is of the digit [0, 9].

Tiiny tiny dataset, 250 images, 25 per digit. Python helpers to create an template, then go in and draw the digits by hand. Another script to split the invidual 28x28px images from the template, id them and label it automatically (based on row) to a csv. The numbers are drawn digitally with varying pens and pen sizes to get some variance in the dataset. This setup also easily enables having someone else come in and do their own hand writing; diversify the data.
During train a slight augmentation is applied. The training loop will train on the dataset images and also slightly modified versions of them. In this case the images are shifted by +-[1-3]px in the x/y directions.
How does the training work actually? The main idea: Feed the convnet the image, compare it's output to expected label, nudge weights accordingly. Run a few epochs until the model has learned the needed patterns.
--mathematical explanation omitted--
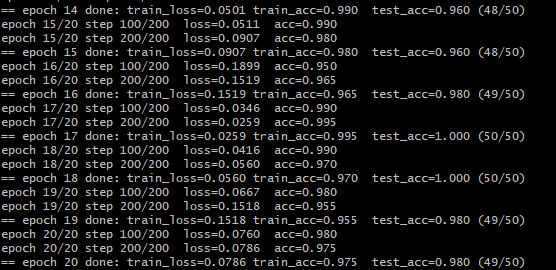
The model learns to classify the input digit very fast with approx 98-100% accuracy based on averaging 10 tests.