Posted on 18.12.2025
Goal: train a food-seeking neural net. Train the model to recognise environment inputs and predict the best course of action to reach its goal.
Methodology: Use Reinforcement Learning in an evolutionary algorithm context, where we are evaluating a certain population of agents and selecting those with highest fitness to create the next generation of children.
What are nematodes? They are these small multi-celled creatures that wiggle around in water to hunt for food. Their - small - neuron structure takes inputs from it's environment through biological sensors and essentially produces movement signals that tell it to either move forward or turn. Perfect application for a small ML model.
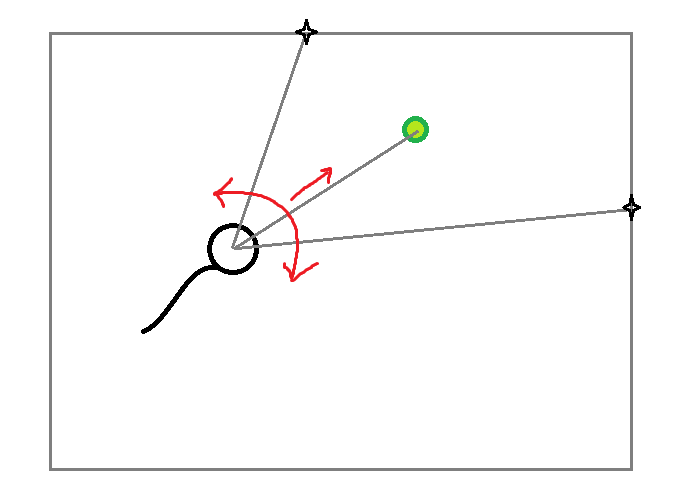
We have a square stage with a nematode and food randomly positioned. The nematode is free to move within the stage. The nematode will get six inputs:
We will then feed this input vector a neural net and inference outputs:
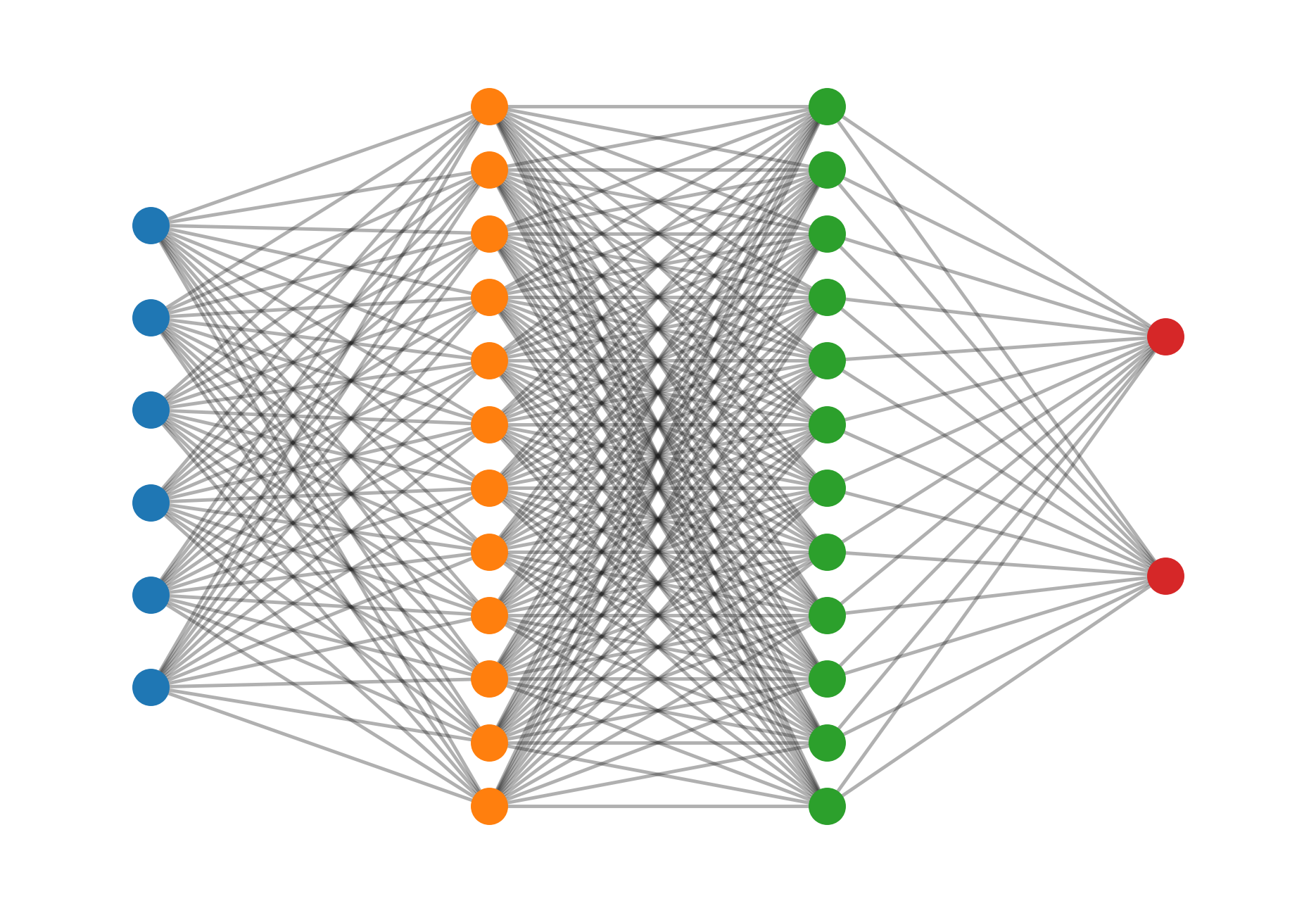
For such a simple task, we really don't need a large model. Initially I chose the architecture as 6->24->24->2, but in testing even this proved too large and i lowered the hidden layer height to 12.
A MLP forward pass is the process of inferencing a model. We have the inputs and from those we go to calculate the first hidden layer:
After computing the linear result for each node, we can activate it to enable our model to learn non-linear properties. A ReLu activation just sets any negative value to 0.0f.
Evolutionary loop runs for LOOP_N times. It creates POP_N amount of population, aka Nematode objects. In a single loop each of these nematode objects compete against each other in the same 8 randomly created environments. The nematodes that fared the best, aka have the highest reward, get to procreate. The next generation of Nematodes is then these elites and their mutated children. This creates an evolutionary pressure for the model weights to learn the optimal ways to move through the stage to reach the food.
Evaluating a single environment is where we set the reward. It runs in steps where on each step we inference the
model and ask it what it wants to do. Every step we give a time step penalty to reward.
(reward -= 0.01f;)
If the model gets closer to the food within the step, it is given more reward scaled to how much closer it got. If the model reaches the food, the highest amount of reward is given and the session evaluation ends. There is an additional penalty for touching the wall, to prevent a wall hugging behaviour.
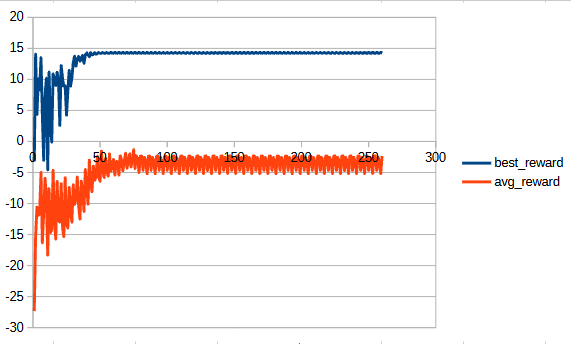
writing the code was quite straightforward. very fun. i had more trouble setting and assessing the ML parameters. In total I probably ran 30-50 training runs to optimize the training params. With the current ones, this trains to a maxima very fast, in only about 50-70 generations it has learned an optimal policy. also what helped me immensely was creating the visualization framework to view what the training is doing in quasi-realtime (i'm just inferencing an elite weight checkpoint from the latest generation when running the script. due to the speed of training one generation, that's "outdated" in seconds)
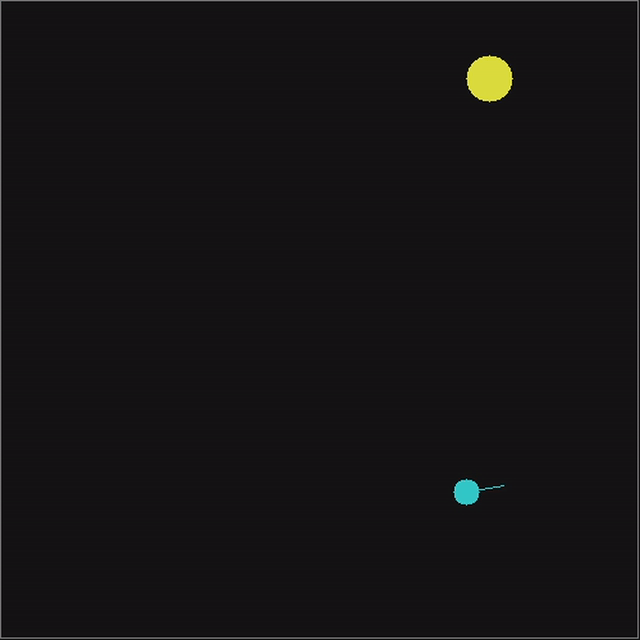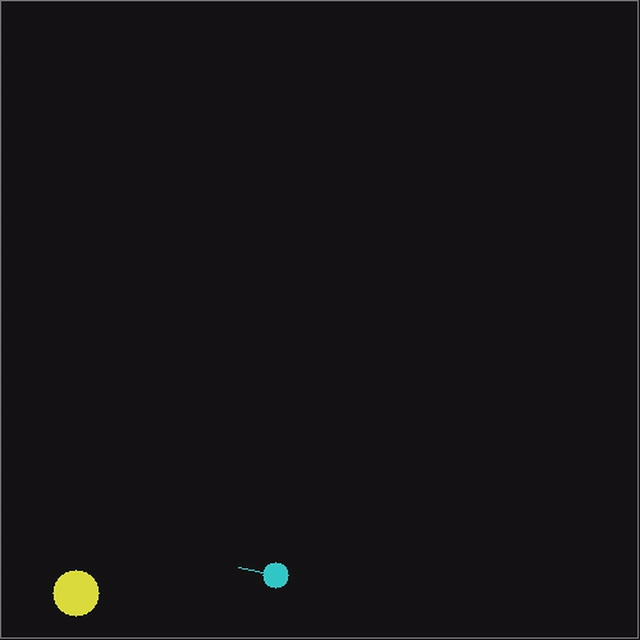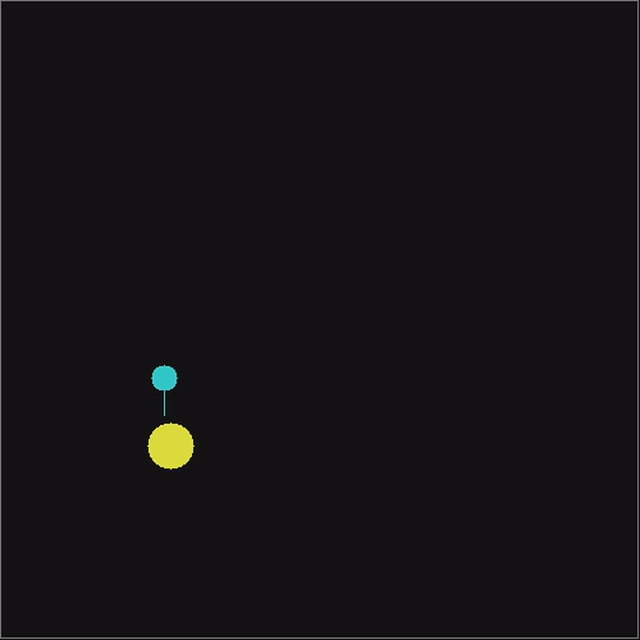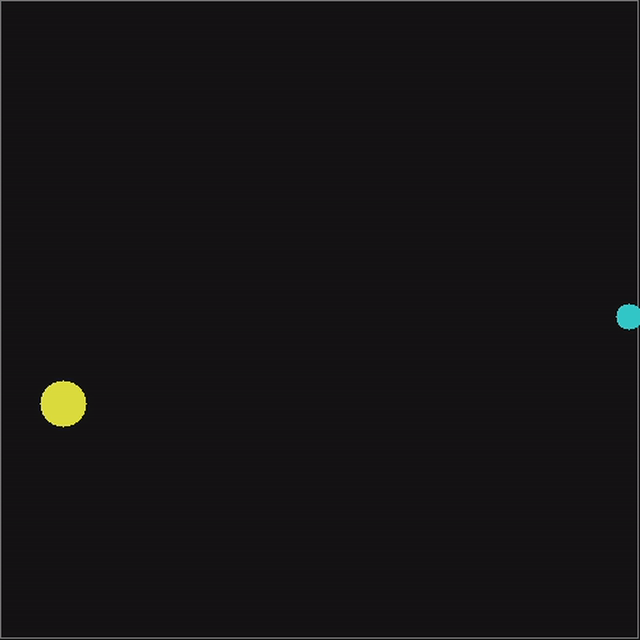
of fucking course, github link here bozo. feel free to look it through and try to understand the code. it's just one main.c for the training and one visualization script. very minimal ML implementation in C, clean, easy to read through and understand what each part does. just the way i like it. I had an AI write the initial version, but frankly it was just slop. the code quality on mine is about 9.2x better. it probably would have worked, but would have been a major pain in the ass to fix, maintain, work on or whatever.
Github here: nematode repo